
متاورس چگونه بر رابطه فین تک ها و مشتریان تاثیر می گذارد؟
شخصی سازی بزرگترین چالش فین تک ها در چند سال گذشته بوده است. سازمان هایی که نتوانسته اند پیشنهادات خود را برای انطباق با این تقاضا تغییر دهند، در حاشیه قرار گرفته اند.

برجسته سازی اثر انسانی
متاورس تعاملات و روابط را “انسانی” تر می کند. کسانی که در اقتصاد جدید و فراجهانی شرکت میکنند، میتوانند با آواتارها در محیطهای مجازی سهبعدی که به نظر آشنا و دوستانه هستند، تعامل داشته باشند. آنها قادر خواهند بود با افراد واقعی ارتباط برقرار کنند. و درست همانطور که پلتفرمهای اجتماعی برندها و شرکتها را به مشتریان/جامعههایشان نزدیکتر کردند، متاورس آن سطح را عمیقتر خواهد کرد.
متاورس تعاملات و روابط را “انسانی” تر می کند. کسانی که در اقتصاد جدید و فراجهانی شرکت میکنند، میتوانند با آواتارها در محیطهای مجازی سهبعدی که به نظر آشنا و دوستانه هستند، تعامل داشته باشند. آنها قادر خواهند بود با افراد واقعی ارتباط برقرار کنند. و درست همانطور که پلتفرمهای اجتماعی برندها و شرکتها را به مشتریان/جامعههایشان نزدیکتر کردند، متاورس آن سطح را عمیقتر خواهد کرد.
پاسخ به رفتارهای مشتری در زمان واقعی
متاورس خدمات مالی را شخصیتر، در دسترستر، ایمنتر و جذابتر برای مصرفکنندگان میکند. در همین حال، جریان های درآمد جدیدی را برای خود شرکت های فین تک باز می کند. تعادل شخصی سازی، امنیت و تجربه محرک اصلی این تغییر است. شرکتهای فینتک روی حجم دادهها نشستهاند: آنها به اطلاعات مربوط به ترجیحات، رفتار و عادات مالی کاربران دسترسی دارند. متاورس میتواند به کمک این داده ها ارائه خدمات را شخصی سازی کنند.
متاورس خدمات مالی را شخصیتر، در دسترستر، ایمنتر و جذابتر برای مصرفکنندگان میکند. در همین حال، جریان های درآمد جدیدی را برای خود شرکت های فین تک باز می کند. تعادل شخصی سازی، امنیت و تجربه محرک اصلی این تغییر است. شرکتهای فینتک روی حجم دادهها نشستهاند: آنها به اطلاعات مربوط به ترجیحات، رفتار و عادات مالی کاربران دسترسی دارند. متاورس میتواند به کمک این داده ها ارائه خدمات را شخصی سازی کنند.
اقتصاد سبز
امروز، ما در یک اقتصاد مبتنی بر دیجیتال زندگی میکنیم و متاورس پیوندی است که همه امکانات دیجیتال را در یک قلمرو مجازی گرد هم میآورد. کمک به صنعت مالی سبز از سه طریق توکنیزه کردن اقتصاد، دسترسی سریع به تجارت کربن و هدایت بودجه تقویت می شود.
امروز، ما در یک اقتصاد مبتنی بر دیجیتال زندگی میکنیم و متاورس پیوندی است که همه امکانات دیجیتال را در یک قلمرو مجازی گرد هم میآورد. کمک به صنعت مالی سبز از سه طریق توکنیزه کردن اقتصاد، دسترسی سریع به تجارت کربن و هدایت بودجه تقویت می شود.
بیشتر بدانید: https://thefintechtimes.com/how-is-the-metaverse-impacting-the-relationship-between-fintechs-and-customers-industry-responds/

 اپراتور فرآیند اتصال یک برنامه در حال اجرا در Google Kubernetes Engine را با پایگاه داده مستقر در Cloud SQL ساده می کند.
اپراتور فرآیند اتصال یک برنامه در حال اجرا در Google Kubernetes Engine را با پایگاه داده مستقر در Cloud SQL ساده می کند.


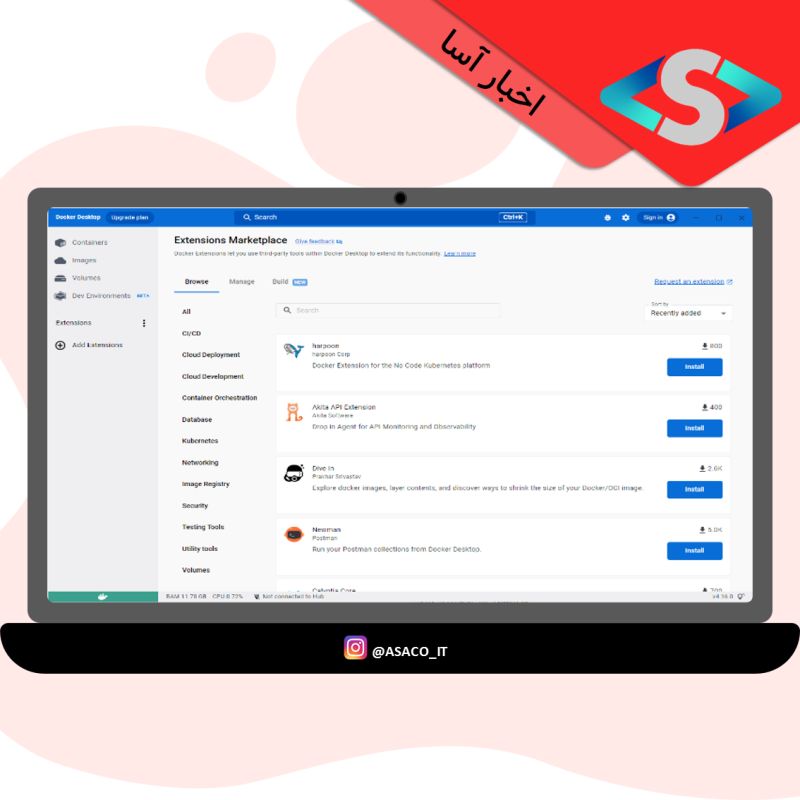 مهم ترین پیشرفت در این نسخه، در دسترس قرار دادن برنامه های افزودنی Docker است، و این نسخه همچنین تعدادی بهبود عملکرد را ارائه می دهد. Docker Extensions برای اولین بار در ماه مه 2022 معرفی شد، مکانیزمی برای افزودن عملکرد و گسترش قابلیتهای Docker Desktop، با یک SDK نیز برای توسعه برنامههای افزودنی در دسترس است. Docker Extensions با تعدادی از شرکای راه اندازی راه اندازی شد، از جمله بسیاری از ارائه دهندگان Kubernetes مانند VMware Tanzu و OpenShift و ابزارهای اشکال زدایی مانند Telepresence. همچنین تعدادی برنامه افزودنی برای کار با ایمن سازی زنجیره تامین نرم افزار، مانند Snyk، Anchore، Trivy و JFrog Xray ارائه شده است. از زمان راهاندازی Extensions Marketplace با 15 برنامه افزودنی راهاندازی اولیه، این میزان با 34 افزونه در حال حاضر بیش از دو برابر شده است.
مهم ترین پیشرفت در این نسخه، در دسترس قرار دادن برنامه های افزودنی Docker است، و این نسخه همچنین تعدادی بهبود عملکرد را ارائه می دهد. Docker Extensions برای اولین بار در ماه مه 2022 معرفی شد، مکانیزمی برای افزودن عملکرد و گسترش قابلیتهای Docker Desktop، با یک SDK نیز برای توسعه برنامههای افزودنی در دسترس است. Docker Extensions با تعدادی از شرکای راه اندازی راه اندازی شد، از جمله بسیاری از ارائه دهندگان Kubernetes مانند VMware Tanzu و OpenShift و ابزارهای اشکال زدایی مانند Telepresence. همچنین تعدادی برنامه افزودنی برای کار با ایمن سازی زنجیره تامین نرم افزار، مانند Snyk، Anchore، Trivy و JFrog Xray ارائه شده است. از زمان راهاندازی Extensions Marketplace با 15 برنامه افزودنی راهاندازی اولیه، این میزان با 34 افزونه در حال حاضر بیش از دو برابر شده است. حمله جدید یک روند اخیر را برجسته می کند. حمله زنجیره تامین از یک وابستگی مخرب به PyPi با همان نامی که هر شب با PyTorch ارسال میشود، سرچشمه میگیرد. “از آنجایی که شاخص PyPI اولویت دارد، این بسته مخرب به جای نسخه از مخزن رسمی ما در حال نصب بود. این طراحی به هر کسی امکان میدهد بستهای را با همان نامی که در فهرست شخص ثالث وجود دارد ثبت کند و pip نسخه ای از آن را بهطور پیشفرض نصب میکند.”
حمله جدید یک روند اخیر را برجسته می کند. حمله زنجیره تامین از یک وابستگی مخرب به PyPi با همان نامی که هر شب با PyTorch ارسال میشود، سرچشمه میگیرد. “از آنجایی که شاخص PyPI اولویت دارد، این بسته مخرب به جای نسخه از مخزن رسمی ما در حال نصب بود. این طراحی به هر کسی امکان میدهد بستهای را با همان نامی که در فهرست شخص ثالث وجود دارد ثبت کند و pip نسخه ای از آن را بهطور پیشفرض نصب میکند.”
 یک پروژه متن باز Eclipse که قادر به تجزیه و تحلیل و ارتقاء برنامه ها از جاوا 8 به جاوا 11 و از جاوا 11 به جاوا 17 است. EMT4J از ارتقاء به نسخه های LTS آینده پشتیبانی می کند. سازمانها توصیه میکنند که اجراکننده جاوا را بهروز نگه دارید تا امنیت و پیشرفتهای عملکردی به دست آید. در همین حال، نسخههای پشتیبانی بلندمدت جاوا (LTS) هر دو سال یکبار منتشر میشوند و پروژههایی مانند Spring Framework 6 اکنون به جاوا 17 نیاز دارند. متأسفانه، پذیرش نسخههای جدید جاوا نسبتاً کند است. به عنوان مثال، در سال 2022، چهار سال پس از انتشار، جاوا 11 توسط کمتر از 49 درصد از برنامه های کاربردی جاوا استفاده شد. ارتقاء یک برنامه کاربردی به نسخه جدید جاوا به این معنی است که توسعه دهندگان باید تمام مشکلات ایجاد شده توسط تغییرات و حذف های داخل جاوا را حل کنند. این شامل عملکردهایی مانند حذف بستههای Nashorn، J2EE و Java، تغییر در APIها و دسترسی به بخشهای داخلی جاوا است که محدودتر شدهاند.
یک پروژه متن باز Eclipse که قادر به تجزیه و تحلیل و ارتقاء برنامه ها از جاوا 8 به جاوا 11 و از جاوا 11 به جاوا 17 است. EMT4J از ارتقاء به نسخه های LTS آینده پشتیبانی می کند. سازمانها توصیه میکنند که اجراکننده جاوا را بهروز نگه دارید تا امنیت و پیشرفتهای عملکردی به دست آید. در همین حال، نسخههای پشتیبانی بلندمدت جاوا (LTS) هر دو سال یکبار منتشر میشوند و پروژههایی مانند Spring Framework 6 اکنون به جاوا 17 نیاز دارند. متأسفانه، پذیرش نسخههای جدید جاوا نسبتاً کند است. به عنوان مثال، در سال 2022، چهار سال پس از انتشار، جاوا 11 توسط کمتر از 49 درصد از برنامه های کاربردی جاوا استفاده شد. ارتقاء یک برنامه کاربردی به نسخه جدید جاوا به این معنی است که توسعه دهندگان باید تمام مشکلات ایجاد شده توسط تغییرات و حذف های داخل جاوا را حل کنند. این شامل عملکردهایی مانند حذف بستههای Nashorn، J2EE و Java، تغییر در APIها و دسترسی به بخشهای داخلی جاوا است که محدودتر شدهاند.